DbLedger Integration Architecture
This section describes the architecture of Deon Digital’s solution for managing contracts written in the Contract Specification Language (CSL) using Deon Digital’s centralized ledger solution (DbLedger) to store contract instances in a tamper-proof manner. This document assumes knowledge of the CSL language, which is documented in Deon Digital CSL Platform Documentation.
Overview
DbLedger is a centralized CSL-specific digital ledger that durably stores contract data. It provides an API (Kotlin interface) to perform the following contract operations on the ledger namely:
Add declarations of CSL source code
Instantiate contracts
Apply events to contracts
Terminate contracts
Replace contracts
Generate reports
The exposed APIs provide an immutable view of the ledger so that the stored data is either read or appended to, which allows reconstruction of the history of changes to the ledger. The following diagram illustrates the architecture of DbLedger.
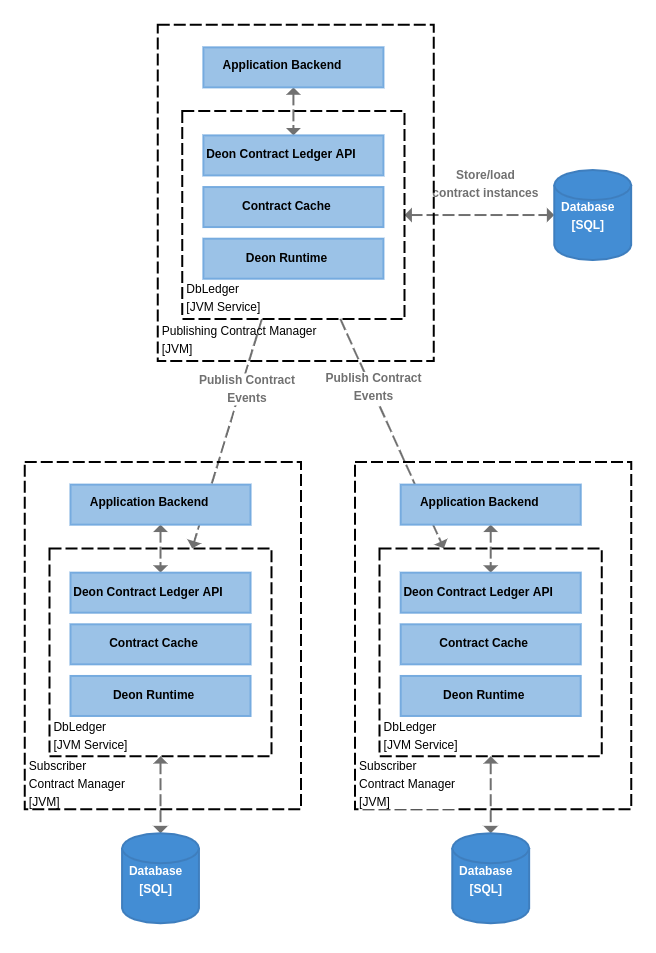
The storage layer (Database) which is used to store ledger data durably is elaborated in Persistent Storage. The caching layer (Contract cache and Deon Runtime) which is used to process the DbLedger API efficiently is described in Caching. The centralized design of DbLedger with support for logical replication is elaborated in Centralization and Replication in DbLedger. DbLedger is implemented as a library in Kotlin and exposed through multiple interfaces (as a REST service and as a Kotlin library that is invoked directly from the client process) which is described in Interfaces. DbLedger requires the client code to process the CSL contracts using The sic code generator or the Language Service.
Persistent Storage
DbLedger uses a relational database system as the underlying storage layer to store contract-related information durably. It uses an ORM (Object-Relational Mapping) library internally to provide portability over multiple relational database systems. Consequently, DbLedger allows flexible integration of various relational database systems as the underlying storage layer in the following modes:
Stand-alone mode where the database system runs as a separate process (e.g., PostgreSQL)
Embedded mode where the database system runs in the same process as DbLedger (e.g., SQLite)
Although DbLedger currently uses a relational database as the underlying storage layer, in the future more storage backends e.g., NoSQL storage systems and streaming systems e.g., Kafka will be supported to better suit any integration needs.
The events that have been applied to a contract are stored with a hash chain that both characterizes the order in which the events were applied and enables tamper detection. The events are cryptographically signed by the relevant parties or systems and the signatures are stored in the ledger entries to guarantee non-repudiation.
Internal Data Storage Model
DbLedger stores contract-related information in a standard relational database system for data persistence while leveraging the benefits of indexing and transactions. Since DbLedger interacts with the underlying relational database system using the Exposed framework, any database backend supported by the framework can be used. For a full list of supported providers, please refer to the Exposed documentation. DbLedger has been tested with the PostgreSQL and SQLite database backends and ships with SQLite as the default storage backend.
DbLedger has a small database schema footprint consisting of only 8 tables. There is no database-specific logic, such as stored procedures, views, or temporary tables, so the maintenance overhead of the underlying database is extremely low. In addition to reducing maintenance overhead, this enables DbLedger to be used with other storate models in the future. The database tables make use of primary key, foreign key, and uniqueness constraints, both to preserve data integrity and to benefit from indexing for data retrieval. The transactional guarantees provided by a relational database are primarily used to update multiple tables atomically.
The database tables are:
Table name |
Purpose |
|---|---|
Contracts |
The current state of the contract and metadata such as instantiation time, arguments, etc. |
Events |
Events applied to a contract |
Declarations |
CSL declarations |
Participants |
Participants in the system. |
Terminations |
Termination information of contracts |
Novations |
Replacement information of contracts |
ContractParticipants |
Reference table for linking participants to contracts |
ContractStateTree |
Checkpoints of the CSL runtime of a contract |
All CSL related types (e.g., event data, contract instantiation information) are stored in a compact binary format in the database that is serialized and deserialized by DbLedger when needed.
Caching
DbLedger caches the data stored in the storage layer to efficiently process the exposed contract operations API. The primary benefit of the cache is the elimination of repeated slow access to the storage layer. Since data is stored in serialized format, caching data also minimizes repeated deserialization costs. DbLedger uses a sized cache that is built on Caffeine. The eviction policy employed by the cache is a variant of the least-recently-used scheme that utilizes frequency sketches to probabilistically estimate the usage of a cached entry. DbLedger maintains separate caches for:
Instantiated contracts
Events applied to a contract
CSL declarations
The use of separate caches allows localization of access patterns (by minimizing unnecessary evictions) and tight translation of cache sizes to memory usage estimations.
The use of caching enables DbLedger to occupy a middle ground in the tradeoff between the space cost of storing the abstract syntax tree of the residual contract after every event application and the time cost of reconstructing the abstract syntax tree of the residual contract from the initial contract and event application history. Please refer to Deon Runtime for more details on the CSL runtime, residual contracts, and their abstract syntax tree representation. DbLedger does not store the abstract syntax tree upon contract instantiation or upon every event application. Instead, it stores regular checkpoints, each consisting of the abstract syntax tree of the residual contract, after a configurable number of event applications since the previous checkpoint. The cache reconstructs the abstract syntax tree of the residual contract from the latest checkpoint thus minimizing data access from the database and speeding up the reconstruction of the contract.
The use of caches also raises issues of data consistency between the database and the cache. DbLedger ensures that the caches are accessed in appropriate critical sections by holding locks while executing the DbLedger API. Moreover, the caches are only updated if the underlying changes to the database are successful. The usage of uniqueness constraints in the database provides an additional safeguard against stale reads from the cache that result in writes to the database.
Centralization and Replication in DbLedger
DbLedger is designed as a centralized ledger solution that provides the view of a single updateable copy of the ledger to a set of parties. A party is a named authenticated identity who can be a participant in a contract and on whose behalf the operations specified in a contract are performed. DbLedger does not perform any identity management but assumes there is a separate component for managing identities.
It supports logical replication of the ledger data at the contract level with a single publisher, multiple subscriber architecture. Thus, a distributed network of running DbLedger processes can be created with:
A single publisher DbLedger process running on behalf of all the parties
Multiple subscriber DbLedger processes running on behalf of one/more parties connected to the publisher process
Only the DbLedger publisher process supports contract operations that can change the underlying ledger. These operations include contract instantiation, event application, contract termination, and contract replacement. The results of changing the ledger are propagated to the subscriber DbLedger processes.
Every DbLedger process is configured to manage the contract data for a set of parties. To guarantee privacy, the publisher DbLedger process replicates data of a contract only to the subscriber DbLedger processes running on behalf of parties who are participants in the contract. The publisher DbLedger process can be visualized as managing contract data for all parties in a network, while the subscriber DbLedger processes contain contract data of a subset of parties in the network.
In addition to logical replication, the storage layer of DbLedger can be configured for physical replication of data for higher availability and fault-tolerance. Thus, a publisher/subscriber DbLedger process can be configured to connect to a relational database system where the data is physically replicated, including both cloud relational database services and self-hosted replicated database systems.
Although not strictly needed for scalability, the DbLedger architecture allows application-level sharding if required. There is no restriction on setting up multiple DbLedger publisher processes to manage disjoint contracts. Since a subscriber process can only be connected to a single publisher process, there are no replication issues (ordering of updates) to worry about when multiple publisher processes are created. The ability to create multiple publisher processes to manage disjoint contracts connected to multiple subscriber processes allows the application to shard data across the DbLedger processes based on load balancing, fault-tolerance, and data security requirements.
The centralized architecture of DbLedger provides an alternative to the decentralized architecture of digital ledger solutions. The decentralized architecture provides the logical view of multiple read-write copies of the ledger to a set of participants. Alternatively, the centralized architecture of DbLedger provides the logical view of a single read-write copy of the ledger and multiple read-only partitioned copies of the ledger. A centralized design is a better fit for applications consisting of intrinsic centralized components (e.g., legally mandated central manager) that need a digital ledger without paying the performance and modeling costs of decentralization.
Interfaces
Embedded (native Kotlin interface)
DbLedger is implemented in Kotlin and exposes a native Kotlin interface to perform contract operations. This interface allows application code to use DbLedger as a library in an embedded fashion in the application. In this case, the client must process the CSL contract code using The sic code generator in order to use the native interfaces.
Helper Services
Language Service
The language service is used to transform the CSL code into abstract syntax trees as explained in Deon Runtime. This also includes type checking the contract. The service is written in Haskell and runs as a separate process. The language service can be invoked to:
Dynamically process CSL code using the REST API (using the
language-service-client)Statically process CSL code using the Gradle plugin that invokes the language service
Statically processing CSL is useful if the CSL code is known when building the application.
In such a situation, usage of the sic plugin (directly, via a JVM wrapper, or a Gradle plugin), removes the need of running the language service when deploying an application.
Instead, the CSL code is translated into artifacts that can be used in JVM code to provide the necessary functionality for type checking and contract/expression evaluation.
Web Service
The web service is used to expose a REST interface to a standalone DbLedger process.
It consists of a web server that handles the REST API requests, invokes the Language Service when needed to load CSL code, and finally invokes the embedded Kotlin interface of DbLedger.
The web service has an OpenAPI endpoint and Swagger UI that can be used to communicate directly with the API or to generate a starting point for building a browser-based application, available at /openapi.yml and /swagger-ui.html respectively.
The OpenAPI specification contains fully-specified schemas for all inputs and outputs of the web service, including error handling.
Putting it All Together in an Application
To summarize, a client application may deploy DbLedger using the following methods depending on application-specific needs:
DbLedger can be deployed as a standalone service, by using the Web Service that implements a well-defined REST API for interacting with contracts. The web service also manages an internal Language Service, which is the component that loads CSL contracts and translates them into their internal run-time representation. Clients are therefore able to use this conversion on-the-fly via the REST API, making it convenient to use in scenarios where one often wants to instantiate a completely new CSL contract.
DbLedger can be run in standalone mode as above, but the application makes use of a type-safe Kotlin interface derived automatically from the CSL source which acts as a wrapper of the generic REST client. This has the downside that one cannot as easily introduce new CSL contracts and work with them in the application, as the Kotlin interfaces are generated based on the CSL source, but on the other hand it allows the application developer to work with a much friendlier and safer interface.
DbLedger can be included in a project as a Maven dependency and its native Kotlin/JVM interface is used for interaction in an embedded mode. This interface is more low-level than the REST API and it requires the caller to supply the low-level contract representation. It is therefore suited for use in a setting where the CSL contract is known beforehand and can be translated to its low-level representation up-front.
In the last two approaches outlined above the sic tool is used to generate “ergonomic” Kotlin interfaces and map CSL types to their Kotlin counterparts.
Since the tool separates the contract operations interface that the application developer will interact with from the connector to the underlying ledger, the same contract operations interface can used to interact with DbLedger in either standalone or embedded mode.
Deployment
All the components in a DbLedger deployment are delivered as containerized modules. The recommended deployment strategy for DbLedger is to use a container platform to deploy the container images for the components.
It is possible to use container orchestration like Docker compose or Kubernetes to manage the deployed components. A demonstration deployment can be downloaded from Docker Hub.